Google、NVIDIA、Meta如何布局?AI下一个重大拐点揭秘

引言
Yoshua Bengio、Yann LeCun 等大佬都曾公开表示,“世界模型”是通往强人工智能的关键路径,因为它让AI不再仅靠死记硬背数据(如大模型那样),而是能像人一样,形成对世界的抽象理解。
“世界模型”是让AI具备“想象力”和“内在认知”的重要范式,它关联着人类认知中的内在“模型概念”,并在近年深度学习与强化学习融合下获得了实证突破。
本文将带领大家了解“世界模型”的前世今生,并对Google、NVIDIA、Meta等当今全球最先进的世界模型实践案例进行深入解读。让我们开启这段奇妙的“世界模型”探索之旅吧!
01
什么是“世界模型”?
人类大脑并不会处理世界中的每个细节。相反,我们依靠由过往经验形成的抽象表征——即“心理模型”(mental model)——来指导自己的决策。即使在事情发生之前,我们的大脑也会持续根据这些模型和以往的行为预测接下来的结果——“如果……会怎么样”。
这正是 AI 领域“世界模型”理念的核心。
相比让 AI 通过在现实世界中反复试错,AI Agent会使用一个“世界模型”(world model)——也就是对环境的学习型模拟——在内部“想象”和探索各种可能的行动序列。通过在脑海中自行模拟,AI 能够尝试并筛选出更有可能实现目标的行动路径。
这种方法优势显著:
首先,极大地节省了资源,因为 AI 无需亲自执行每一个可能的动作;
更重要的是,让 AI 的行为方式更接近人类大脑——能够预测、设想不同场景,并计算其后果。
具体来说,世界模型是一类生成式AI系统,通过多样化输入数据学习现实环境的内部表征,包括物理特性、空间动态和因果关系,而后利用学习到的表征来预测未来状态,在内部模拟一系列动作,从而支持复杂的规划与决策,无需在真实世界进行反复试验。
经典的世界模型通常包括3个组成部分:
a 状态表征模型:将原始观测(如高维图像)编码为简洁的潜在状态;
b 动态模型:预测给定当前潜在状态和动作下环境的下一个状态分布;
c 奖励模型(可选):预测潜在状态下的价值或奖励信号。
Yann LeCun将世界模型定义为:“观察环境并基于当前知识预测未来可能发生的事情”的系统。与纯粹反应式的模型不同,世界模型关注对环境因果结构和动态规律的内部拟合——如同大脑预测棒球飞行轨迹以提前挥棒击球一样,AI 也能凭借世界模型进行前瞻性的反应。
02
“世界模型”的起源和发展
在理论源起上,“世界模型”这一概念与控制论和强化学习中的模型化思路密切相关。经典强化学习中,有基于模型(Model-Based)和无模型(Model-Free)两派。前者要求智能体学习环境转移模型,再据此规划;而后者直接从试错中学习策略。
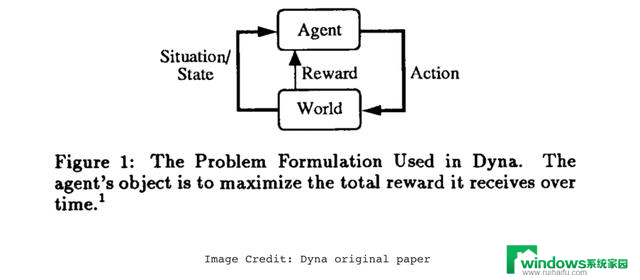
“世界模型”背后的核心思想早在上世纪90年代的AI研究中就已出现,最具代表性的早期工作之一是Richard S. Sutton于1990年提出的Dyna算法。这是一种基础的基于模型(Model-Based)的强化学习方法,将学习、规划和反应能力融为一体,让智能体具备以下能力:
通过尝试动作来探索环境,并用强化学习的方式,不断试误总结什么策略有效;
随着时间推移,逐步学会环境的规律,建立对世界的内部模型,以预测接下来可能发生的事情;
智能体能在“脑海”中利用这个世界模型进行推演和规划,而不必在真实世界反复试验,节省现实中的代价和风险;
一旦环境中发生变化,智能体可以凭借已有经验迅速作出反应,无需每次都从头规划,从而实现即时决策。
时间来到2018年,David Ha和Jürgen Schmidhuber的论文“World Models”,是一个关键里程碑,被视为深度世界模型的开端。他们用生成型循环神经网络(RNN)以无监督方式对流行的强化学习环境(如赛车游戏和二维类射击游戏)进行建模,这个世界模型能够学习游戏画面的压缩空间表征以及随时间变化的动态。
具体来说,该系统包含三个部分:
视觉组件:变分自编码器(VAE)将高维观测(像素图像)压缩为低维潜在表征;
记忆组件:混合密度循环网络(MDN-RNN)根据当前潜在状态和智能体动作预测下一个潜在状态;
控制器:接收潜在状态和RNN的隐藏状态,输出动作。
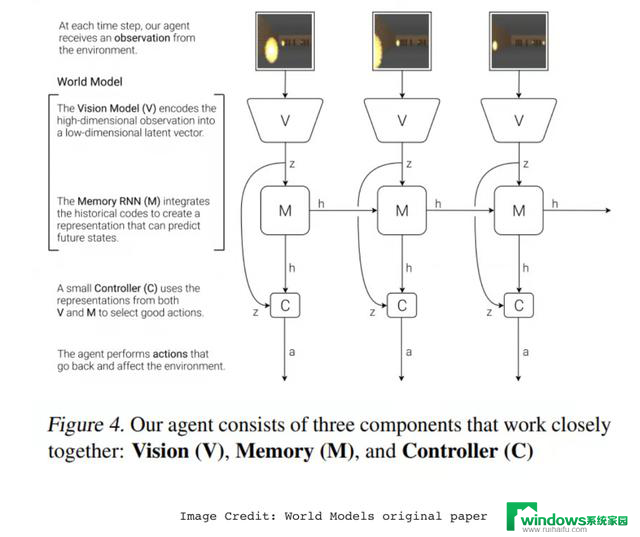
Ha 和 Schmidhuber 展示了,策略(控制器)可以完全在学习到的模型“梦境”中进行训练,并且之后能够成功转移到真实的游戏环境中。这为构建能够像人类一样“想象、规划和行动”的智能体奠定了基础,并激发了人们对基于模型(Model-Based)方法的兴趣。
此后,2019年DeepMind发表的MuZero算法、2022年LeCun提出的JEPA表征模型、2023年关于大语言模型蕴含世界知识的研究、2024年的视频生成模型Sora、2024年的城市环境生成模型UrbanWorld。以及在机器人、自动驾驶、虚拟社会模拟等领域的应用探索(如DayDreamer、Smallville、Vista等),一系列成果进一步让世界模型成为通往“类人智能”的热门思路之一。
03
那些当今世界最前沿的世界模型
【以下我们将详细介绍几个当前全球范围内最先进的世界模型,它们采用了不同的底层架构和工作原理,却都体现了非常出色的设计思路。】
Google DeepMind:Dreamer
由 Google DeepMind 的 Danijar Hafner 团队开发的 Dreamer 系列智能体,其最新版(2025年4月)的通用强化学习算法 DreamerV3,能够在无需更改超参数的情况下,处理超过150种不同任务。然而,最大的突破在于,这是首个能够在 Minecraft 游戏中“从零开始”挖掘钻石的算法——完全没有借助任何人类示例,仅靠自身“想象力”和默认设置实现。这不仅是强化学习的成就,更是世界模型的里程碑。DreamerV3 能够学习环境的世界模型,并用它来“想象”接下来可能发生的事情,从而做出更优的行动决策。
DreamerV3 由三大部分组成:
World Model :使用递归神经网络(RNN),具体来说是递归状态空间模型(RSSM),将智能体看到的内容(如图像或数值输入)压缩为更简单的潜变量表征。这种方式有助于模型保留对过去事件的记忆,并更好地预测未来状态。在给定一个动作的情况下,模型能够预测下一个状态、预期奖励以及该回合是否继续。值得注意的是,与许多近期流行的AI架构不同,DreamerV3 并不使用 Transformer,而是完全依赖递归模型。
Critic:负责评判世界模型“想象”出的结果有多好或多坏。因为奖励可能波动很大,DreamerV3 采用了精细的归一化和基于分布的评分方式,确保即使奖励稀疏或不稳定,学习过程依然稳定。同时,它还采用参数的滑动平均来进一步稳定学习。
Actor:根据 World Model 和 Critic 提供的见解,决定采取何种最佳动作,在追求即时奖励与探索新策略之间取得平衡,避免陷入局部最优。DreamerV3 会细致归一化预测的回报,即使奖励稀少,也能保持均衡的探索动力。
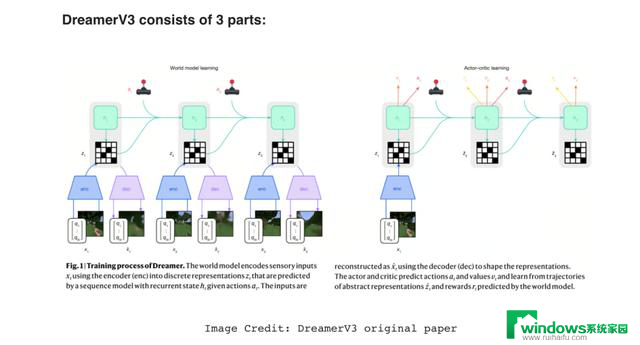
在World Model中,DreamerV3 引入了多个巧妙的增强方法。例如:使用 KL 散度用于衡量模型预测与现实之间的差异,相当于给模型一个“现实检查”,如果预测偏离现实,模型就会对自身进行调整;使用 Free bits 机制避免模型因微小的不准确而过度修正;使用 Symlog 编码将现实中大幅度的正负数字信号(比如奖励或像素值)压缩到可管理的数值范围,帮助系统稳定持续地学习;使用 Two-hot 编码将学习目标分散到两个相邻的类别上,使预测更加平滑,整个学习过程更简单、更稳定。
Google DeepMind:Genie 2
Genie 2 是 Google DeepMind 在世界模型领域的另一个有趣进展。只需一张图片作为提示,Genie 2 就可以创建可供人类和 AI 系统通过键盘和鼠标操作的可玩虚拟世界。它支持长时记忆、一致性的世界生成,以及从共享起点出发的反事实模拟,并展现了一系列新兴能力,例如处理角色移动、模拟物理动态(如重力、光照、反射)、建模与物体和非玩家角色(NPC)的互动。
Genie 2 可用于为具身智能体生成多样化的训练环境,让构建能够适应复杂虚拟世界中各种任务的通用系统成为可能。结合类似 SIMA 的智能体,Genie 2 可以生成全新的 3D 场景来测试指令跟随能力,使智能体能够利用自然语言指令在全新环境中导航和行动。
具体来说,Genie 2 是一种自回归潜空间扩散模型,在大规模视频数据集上进行训练,能够逐帧生成视频。其过程如下:
首先,使用自动编码器将视频帧压缩到潜空间;
基于 Transformer 的自回归模型根据前面的潜变量帧以及智能体的动作预测下一个潜变量帧;
接着,应用潜空间扩散过程,对预测的潜变量进一步优化和生成真实感的视频帧;
最后,将潜变量解码为可视化的视频帧。
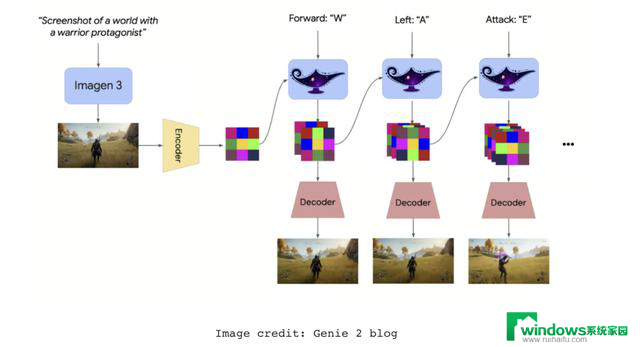
这种架构使 Genie 2 能够在低维潜空间中运行,随时间对用户或智能体的输入做出响应,并生成逼真且一致的视频输出。
NVIDIA:Cosmos
NVIDIA 在世界模型领域的贡献很难被忽视。NVIDIA 对物理AI(Physical AI)的专注推动了名为Cosmos 的模块化“世界基础模型平台”的开发。
Cosmos 平台包括三大主力模型系列:Cosmos-Predict1、Cosmos-Transfer1 和 Cosmos-Reason1。
Cosmos-Predict1
用于模拟视觉世界随时间的变化。通过超过一亿段视频学习通用的物理世界动态,并可在较小任务数据集上针对特定目标进行微调,实现通过文本、动作或相机输入等方式进行可控生成。
Cosmos-Predict1包含两类模型:
扩散模型(如 Cosmos-Predict1-7B-Text2World):通过在潜空间对噪声去噪,根据文本生成视频
自回归模型(如 Cosmos-Predict1-13B-Video2World):类似 GPT,根据先前上下文逐 token 生成视频帧
Cosmos-Transfer1
直接构建于 Cosmos-Predict1 之上,并为其赋予强大的自适应多模态控制能力。 让用户可以利用多种空间控制信号(如分割图、深度图、边缘图、模糊的视觉输入、高清地图和 LiDAR 数据等)来引导世界生成过程。
为了有效处理不同模态输入,NVIDIA 为每种模态(如深度、边缘等)都添加了独立的 ControlNet 分支。这些控制分支独立训练,实现了较高的内存效率和灵活性,并支持细粒度的控制——例如,可对前景物体细节强调边缘,对背景几何体强调深度等。同时,通过时空控制图动态地为不同输入在空间和时间范围内分配权重。因此,Cosmos-Transfer1 能在不到5秒的时间内生成5秒720p的视频,实现实时推理。
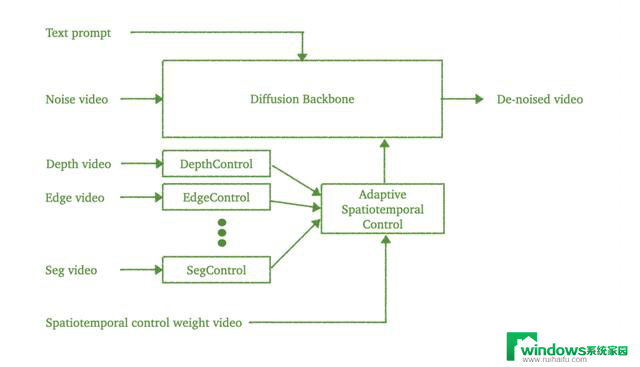
Cosmos-Reason1
Cosmos-Reason1 通过利用 Predict1 的模拟世界和 Transfer1 的精炼视觉来做出明智决策,实现物理 AI 系统的闭环。该模型(提供8B和56B参数规模)能够推理发生了什么、接下来会发生什么,以及在真实物理和环境动态下可行的动作。它围绕两大推理支柱展开:
物理常识:关于空间、时间、物体永久性、物理规律等一般性知识
具身推理:在物理约束下的基于代理的决策(机器人、人类、自动驾驶车辆)
有趣的是,Cosmos-Reason1 采用混合 Mamba-MLP-Transformer 架构,对长序列推理进行了优化:
Mamba 在捕捉长距离依赖方面表现优异,提升整体效率;
Transformer 提供完全自注意力机制,对捕捉短距离依赖和实现高级抽象至关重要,进一步提升了精度;
最后,MLP 层在 Mamba 和 Transformer 层之间提供强大的非线性变换,有助于稳定学习,并作为信息整合的瓶颈,尤其适合跨模态(比如视频+文本)的应用。
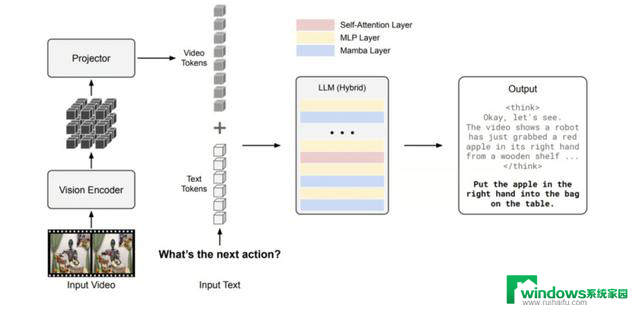
总体来看,Cosmos-Predict1、Cosmos-Transfer1 和 Cosmos-Reason1 共同构成了物理 AI 的一体化基础——Predict1 用于模拟真实世界的动态,Transfer1 实现了跨模态的细粒度可控视频生成,Reason1 则负责对物理世界进行理解和推理,从而做出具身决策。它们协同作用,为智能体提供了一个统一的流程,使其能够感知、生成并推理复杂的现实环境。
Meta:Navigation World Model (NWM)
Meta及其首席AI科学家Yann LeCun认为,要在未来十年内实现“类人智能”,必须依赖能够进行推理和规划的世界模型。因此,Meta的AI研究机构FAIR也在积极转向世界模型的开发,其中研究之一就是与纽约大学和伯克利AI研究院合作研发的Navigation World Model(NWM)。
导航能力对于智能体来说极为关键——尤其是那些能“看见”并“移动”的智能体,比如机器人或游戏中的虚拟助手。在这里,NWM 就像一个智能视频生成器,能够根据智能体过去的位置和目标,想象智能体接下来会看到什么。它可以模拟可能的移动路径,并检测是否可以达到目标。NWM 不再依靠固定规则——它可以根据新的指令或约束及时调整自己的计划。
在技术核心上,NWM 采用了强大的条件扩散Transformer(Conditional Diffusion Transformer,CDiT)。CDiT 遵循扩散式的学习过程,但相较于标准的扩散Transformer(如 DiT),在大幅降低注意力计算复杂度方面有明显提升。CDiT 使用交叉注意力(cross-attention),而不是对所有token都进行自注意力,这使其能够扩展到更长的上下文窗口和更大的模型(参数最高可达10亿),并且相比DiT拥有4倍的FLOPs节省。
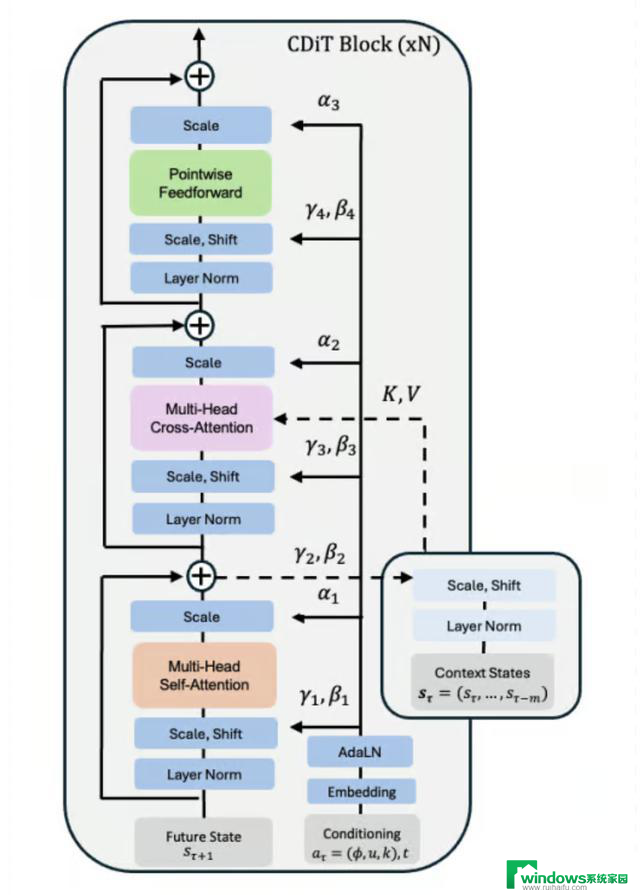
NWM 用于智能导航还有其他关键优势:
它在大量来自人类和机器人的第一人称视频数据上进行训练;
一旦训练完成,它能够通过模拟并检查到达目标的各种路径,来规划新的路线;
该模型规模庞大(约10亿参数),具备理解复杂场景的能力;
NWM 甚至可以适应新环境——只需一张参考图片,就能想象出完整的导航路线可能的样子。
这些特性使 NWM 成为构建智能导航系统时灵活且具有前瞻性的工具。
04
为什么世界模型很重要?
毫无疑问,世界模型是 AI 未来不可或缺的关键拼图。它为 AI 解锁了多项关键能力:
规划与决策:通过拥有世界模型,智能体可以“想象”不同动作策略下未来状态的序列,从而制定最佳方案。这正是基于模型的强化学习的本质,使得智能体能前瞻性地做出多步规划与决策。
效率:在现实世界(或模拟器)中靠试错学习既昂贵又缓慢。世界模型让智能体能够从模拟经验中学习(类似于“脑内练习”),显著减少了真实世界互动的需求。
泛化与灵活性:优秀的世界模型能捕捉环境的普遍特性和底层动态,让智能体能够推理并应对训练时未遇到的新情况。
更丰富的信息基础:世界模型能够接收和处理比语言模型更多的原始信息(如视频流),因而有潜力为 AI 提供更丰富、真实的现实世界基础。
迈向通用智能:许多研究者认为,世界模型是实现更通用 AI 认知能力的关键一步。它们赋予 AI 一种“想象力”以及对世界运行机制的直观理解——这是人类常识、推理和解决问题能力的前提。
“我们需要能够理解世界的机器,需要能够记忆、拥有直觉和常识、能够像人一样推理和规划的机器。”
——Yann LeCun
参考资料:https://www.turingpost.com/p/topic-35-what-are-world-models
FuturePulse
历史文章
李飞飞ReKep论文解读:大模型直接驱动机器人操作,无需数据集
前沿论文解读:Physical Intelligence的通用机器人模型π0
从强化学习到AI药物研发:离治愈所有疾病还有多远?
万字长文解析Pocket FM:全球最大的AI UGC内容平台
从实验到实用:Deep Research 诞生背后的故事
最懂AI商业化的人告诉你:市场选择、定价模式和经济模型的秘密
谷歌RL大佬David Silver:智能体将实现自主学习
Open AI姚顺雨:AI即将进入下半场
Cerebras创始人深度采访:英伟达最大的弱点是什么?
万字长文:深度对话50位谷歌高管,揭秘谷歌的“AI追赶之路”
关于FuturePulse
我们关注足以影响世界的“大变化”,重点关注AI、机器人、宏观等方向。
我们的目标是帮助对相关领域感兴趣的人士,在这个信息过载的时代,高效获取最有价值的信息。形式不限于重大事件摘要、海外内容编译、关键论文解读等,也期待未来可以组织一些有趣的活动。
你有两种方式支持我们:1)关注并星标我们——星标之后可以保证更新及时触达。2)为本文点“
Google、NVIDIA、Meta如何布局?AI下一个重大拐点揭秘相关教程
- 微软开源了操作系统,注释中藏着一个大秘密!如何揭开微软操作系统的神秘面纱?
- Microsoft 今年 9 月将发布 6 个重大公告: 关键信息揭晓
- 微软Win11 24H2 RP 26100.2152预览版发布:全新功能和改进亮点揭秘
- AI应用大爆发,AMD XDNA架构拿下X86 AI第一城,引领AI技术革新!
- 安兔兔榜单揭秘:处理器究竟有多重要?揭秘实情!
- 微软AI助手Copilot上线,真身居然是Edge?揭秘微软AI助手Copilot的神秘身份
- AMD下一代移动处理器不支持Win10?真相揭秘!
- Zed编辑器Windows版开发受阻,难题如何攻克?解决方法大揭秘
- AMD Zen5性能暴涨40%的秘密:独享AVX-512指令集大升级揭秘
- a16z对谈:AI领域三大支柱企业深度分析,英伟达、OpenAI和Scale AI震撼揭秘
- 深耕Windows优势领域,助您解锁更多商机
- AMD Ryzen 5 9500F性价比如何?与Intel入门级CPU相比如何选择?
- 使用 OpenUSD 和 SimReady 资产构建 AI 工厂,优势何在?
- 加强CPU与高性能人工智能服务器软硬件协同攻关,开展人工智能芯片与大模型适应性测试
- 英伟达拿下全球94%的独立GPU市场!——行业霸主的崛起
- Windows 11 25H2升级改进,或许终结蓝屏和死机问题